2026 年 3 月 6 日凌晨,OpenAI 开始把 GPT-5.4 推向 ChatGPT、API 与 Codex。真正值得看重的并不是“榜单谁高谁低”,而是它把模型能力往“更能交付实际工作”推了一步。对长期使用 chatgpt 镜像、同时把 Claude 也拉进工作流的人来说,这次更新很适合重新跑一轮并排测试。
如果你想立刻自己试,不必先折腾官方账号或支付链路,可以直接在 AIMirror GPT 中文站 里同时打开 GPT-5.4 和 Claude,对同一份提示词做并排输出。对 chatgpt 镜像 用户来说,这比看热搜标题更接近真实答案,因为你最终关心的是这代模型在你的任务里能不能少返工、少出错。

1. 为什么这次更新对 chatgpt 镜像 用户更有感
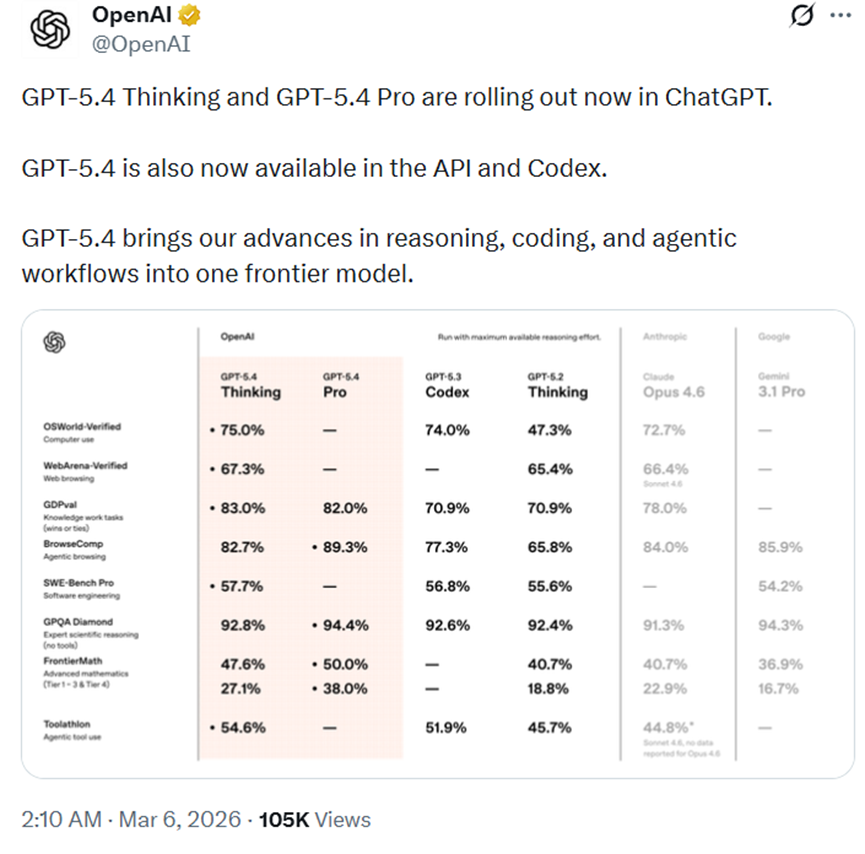
很多版本升级在发布会当天很热,过几天就淡了,因为用户很快发现自己每天的工作方式并没有变。但 GPT-5.4 这次不太一样。它被热议,不只是因为跑分更高,而是因为它在标准化专业任务上的完成度明显抬升了。OpenAI 公布的 GDPval 数据里,GPT-5.4 达到 83.0%,而 GPT-5.2 是 70.9%。这个差距放到日常工作里,并不是抽象的数字变化,而是报告骨架、财务说明、研究摘要、项目纪要这些内容更接近可直接采用的状态。1
对于主要通过 chatgpt 镜像 干活的人来说,这个变化尤其明显。镜像站用户本来就更重视“能不能稳定干活”,而不是“能不能第一时间抢到官方新功能”。如果一个模型单轮输出看起来更聪明,但做表格会错公式、做总结会漏条件、写文档会乱结构,那它在真实工作里仍然要被人工补刀。
这也是为什么很多 Claude 用户会突然紧张。Claude 在长文阅读、语言质感和细腻表达上依然有自己的位置,但当团队更关心的是结构化结果、规则遵守和连续执行时,GPT-5.4 的吸引力会直接得多。
| 观察维度 | GPT-5.4 的变化 | 对 chatgpt 镜像 工作流的影响 |
|---|---|---|
| 专业标准任务 | Professional 评测明显高于 GPT-5.2 | 报告、报表、会议纪要更少返工 |
| 结构化输出 | 格式跟随更稳,漏项更少 | 模板文档、表格、清单更容易直接复用 |
| 多轮连续性 | 长任务中更能记住前置约束 | 少一点“越做越偏”的纠偏成本 |
| 工具协同 | 检索、浏览、执行更连贯 | chatgpt 镜像 的多模型协作价值更高 |
2. 真正拉开差距的,不是聊天,而是电脑操作
如果只是比聊天体验,模型之间的差距有时会被语气、风格和个人偏好放大。但 GPT-5.4 这次最关键的变化,不在于回话更像人,而在于它更像能接手一段完整操作流程的执行者。电脑操作、截图理解、网页定位、表单录入、后台检查,这些过去最容易把人困在机械重复里的任务,现在开始成为它的主战场。
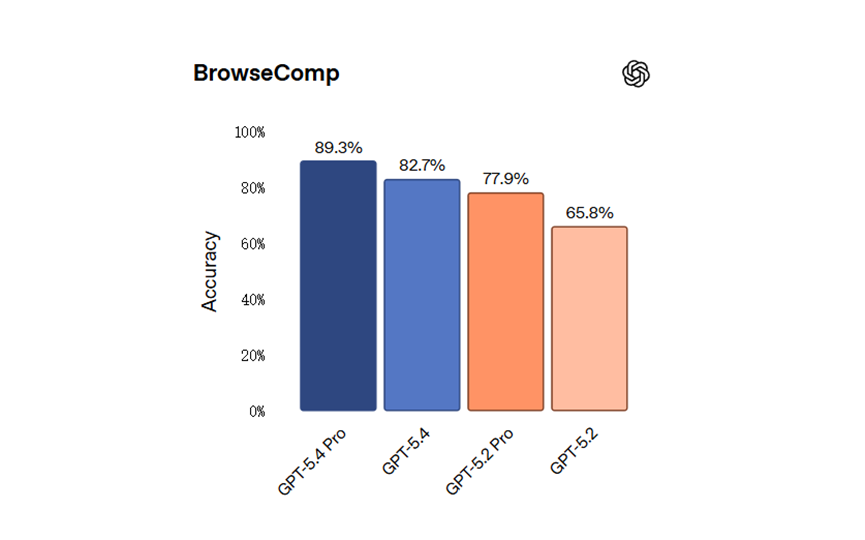
OpenAI 公布的 OSWorld-Verified 分数里,GPT-5.4 是 75.0%,比 GPT-5.2 的 47.3% 高出一大截;在带工具的 MMMU Pro 上也继续领先。原始微信文章里提到的房产税门户和业主协会网站测试,说法虽然偏媒体稿,但抓住了核心事实:电脑操作一旦稳定,模型价值就不只是“更会回答”,而是开始碰到真正能替人完成动作的边界。12
这件事为什么和 chatgpt 镜像 有关?因为镜像站用户常常不会只用一个模型,也不会只让模型写文案。很多人已经在拿多模型处理邮件、CRM、表格、知识库、客服话术和浏览器表单。过去这些流程经常是“Claude 负责理解,ChatGPT 负责补代码,人再负责点网页”。现在 GPT-5.4 往前走一步之后,这条链路有机会缩短成“模型先做,人再审”。
对于运营、客服、行政和中后台岗位来说,这种变化比单纯写作能力提升更实在。真正耗时的地方从来不是写一句总结,而是打开多个系统、核对字段、复制数据、补回表格。如果它能把这些动作连续串起来,chatgpt 镜像 就会更像一个可以调度执行层的工作台。
3. 放到编码和工具链里看,Claude 的压力会更直观
程序员对 GPT-5.4 的感受,往往和普通内容用户不一样。过去大家讨论编码模型,常常聚焦“代码能不能写对”“测试能不能过”“Bug 改得干不干净”。这次更重要的变化是,它把 GPT-5.3-Codex 的一部分前沿编码能力并进主线模型,意味着写代码、看报错、翻日志、跑浏览器测试、补说明文档这些动作,不再需要由几个模型拼起来完成。2
OpenAI 公布的评测里,GPT-5.4 在 SWE-Bench Pro 上是 57.7%,高于 GPT-5.2 的 55.6%;在 Tool use 和 BrowseComp 这种更接近真实研发流程的任务里,提升比单纯代码题更明显。换句话说,它的优势不只在“哪道题更会做”,而在整个研发回路更完整。需求含糊时,它更适合先读上下文;实现完成后,也更愿意自己跑命令、看结果、做核验,而不是把一堆假设抛回给你。2
如果你平时就在 chatgpt 镜像 里切不同模型,这里特别适合做一次并行验证。把 Claude 和 GPT-5.4 放进同一套研发验收标准里,而不是只比较一句 prompt 的表面回答,差异会很快暴露出来:
你现在是资深工程师。请阅读仓库、拆解需求、给出修改方案,并在完成后自检:
1. 不要跳过现有代码结构和命名风格
2. 先列风险点,再动手修改
3. 补齐必要测试或验证步骤
4. 输出变更摘要、残余风险和回滚点
在这种任务下,Claude 往往仍然更擅长把问题讲透,把边界条件说清;GPT-5.4 更突出的则是执行段和核验段。也正因为如此,chatgpt 镜像 用户没有必要争论“谁绝对最强”,更应该关心“谁应该站在哪个工位上”。
4. 更像人在协作,重点不在情绪,而在不中途散架
很多人说模型“更像人”,其实并不是在夸它更会聊天,而是在抱怨过去的模型一旦任务拉长,就很容易把事情做散。前几轮还记得背景,后几轮就忘掉前提;工具该用的时候不用,不该乱试的时候又频繁误触。原始文章里提到的两个变化很关键,一个是任务中途更愿意暴露思路,另一个是记忆和工具检索能力提升,这两个点叠起来,带来的不是情绪价值,而是复杂任务更不容易崩。1
以前做长链路工作流,常见痛点是前面花很多轮把目标讲清楚,模型开头答得也不错,做到第三步第四步时却把早先条件忘掉。GPT-5.4 把任务连续性做得更稳之后,个人用户感受到的是少打几轮补丁,团队用户感受到的则是模型更容易嵌进标准作业流程。对 chatgpt 镜像 平台而言,这一点尤其重要,因为平台价值从来不只是“能访问”,而是“能稳定跑完”。
工具检索的变化也很容易被低估。工具一多,提示词会迅速膨胀,模型每次开工前都要先重新吃一遍说明文档,token 被白白烧掉,响应也会变慢。GPT-5.4 现在更像会临场查手册的同事,不需要你每次都把所有工具用法整段贴上去。微信原文提到工具检索可让 token 消耗下降 47%,关键不在省几分钱,而是让模型在复杂工具环境里不再那么笨重。1
{
"task": "读取客服邮箱附件,提取关键字段,写回 CRM,并生成日报",
"model": "gpt-5.4",
"success_criteria": [
"字段映射准确",
"失败步骤可回溯",
"日报格式固定",
"单次任务可在 10 分钟内闭环"
]
}
这种任务以前通常要拆给脚本、人工复核和几个工具页面,现在它开始有机会把这些碎片重新收拢。
5. Claude 用户现在要不要切过去?别一刀切,但要尽快重测
看到 GPT-5.4 上线,很多 Claude 用户第一反应是“是不是该全部切过去了”。我的判断是不需要这么粗暴。模型替换不是换主题皮肤,它会牵动提示词模板、审阅习惯、接口成本、工作流路径和团队协作方式。Claude 依然适合很多长文理解、细腻表达、慢思考推演的任务,尤其是当你已经有一整套成熟模板时,迁移成本不小。
但如果你的任务重心已经往执行型工作移动,比如需要同时处理文档、网页、截图、表格、命令行和浏览器测试,那 GPT-5.4 的确值得尽快拉进主流程试跑。因为它的提升并不只是“回答更强一点”,而是工作边界更宽了一块。原来需要“模型给方案,人去执行”的环节,现在更可能变成“模型先做,人再审”。这一步对 chatgpt 镜像 场景影响很大,因为镜像站恰好最适合做多模型交叉验证和成本对照。
更稳妥的做法,是把任务按环节切开:前置分析继续交给 Claude,执行和工具调用交给 GPT-5.4;或者反过来,让 GPT-5.4 先给结果,再让 Claude 做语言优化和风险复核。真要跑对照,我建议至少选三类任务:一个写文档,一个带工具,一个长上下文。每类任务记录第一次通过率、人工补刀时长、token 成本和最终可交付质量。这样得到的结论,比任何一句“超过 Claude”都更靠谱。
6. 上线渠道和价格已经明确,评估时别只盯单价
截至 2026 年 3 月 6 日,OpenAI 已明确说明 GPT-5.4 正在逐步推送到 ChatGPT、Codex 和 API,开发者可直接调用 gpt-5.4,复杂任务还可用 gpt-5.4-pro。在 ChatGPT 侧,GPT-5.4 Thinking 当天开始替换 GPT-5.2 Thinking,旧版会保留三个月,并在 2026 年 6 月 5 日退役。2
价格方面,标准 API 费率也已经公开:GPT-5.4 输入是每百万 token 2.50 美元,缓存输入 0.25 美元,输出 15 美元;gpt-5.4-pro 则更贵。很多人看到这个价格就直接下结论说“又涨价了”,但这里不能只盯单价。如果它真的把返工轮次、工具说明冗余和错误修复次数压下来,总成本未必更高。对常跑长任务的人来说,少一轮重试,往往比单 token 降几毛钱更有意义。3
站在 chatgpt 镜像 用户的角度,这个判断更简单。你完全没必要先上官方订阅再试错,可以先在镜像里跑一轮高频任务,看结果是否值得长期迁移。
7. 一份适合今天就跑的实测清单
如果你今天就想判断 GPT-5.4 值不值得纳入主流程,别先做抽象争论,直接拿任务说话。最推荐的做法,是各选一类专业输出、一类执行型任务和一类研发任务。专业输出可以用提案框架、财务说明、研究纪要;执行型任务可以用网页录入、后台核对、信息搬运;研发任务可以用改 Bug、补测试。每类任务统一记录四个指标:第一次通过率、人工补刀时长、token 消耗和最终可交付质量。
如果你本来就在 chatgpt 镜像 里用多模型协作,这一步会非常方便。把 Claude 和 GPT-5.4 放在同一条工作线上,只看谁更适合哪个位置。对内容策划、研究写作和复杂对话,Claude 仍然很有竞争力;对执行闭环、工具调用和编码协作,GPT-5.4 已经明显往前迈了一步。
如果你想快速完成这轮实测,最省事的入口依然是 AIMirror GPT 中文站。它适合把同一份任务同时压给 GPT-5.4、Claude、Gemini 等模型做并排输出。除此之外,也可以把 ChatGPT 镜像站、aicnbox.com 和 Gemini Tool 作为备用线路或专项补充。
我的结论很简单:GPT-5.4 不一定在每件事上都把 Claude 挤到没空间,但它确实把“能不能真正干活”推到了一个新阶段。谁更适合你,答案不在热搜标题里,在你每天那三五个重复、昂贵、最容易出错的任务里。
脚注